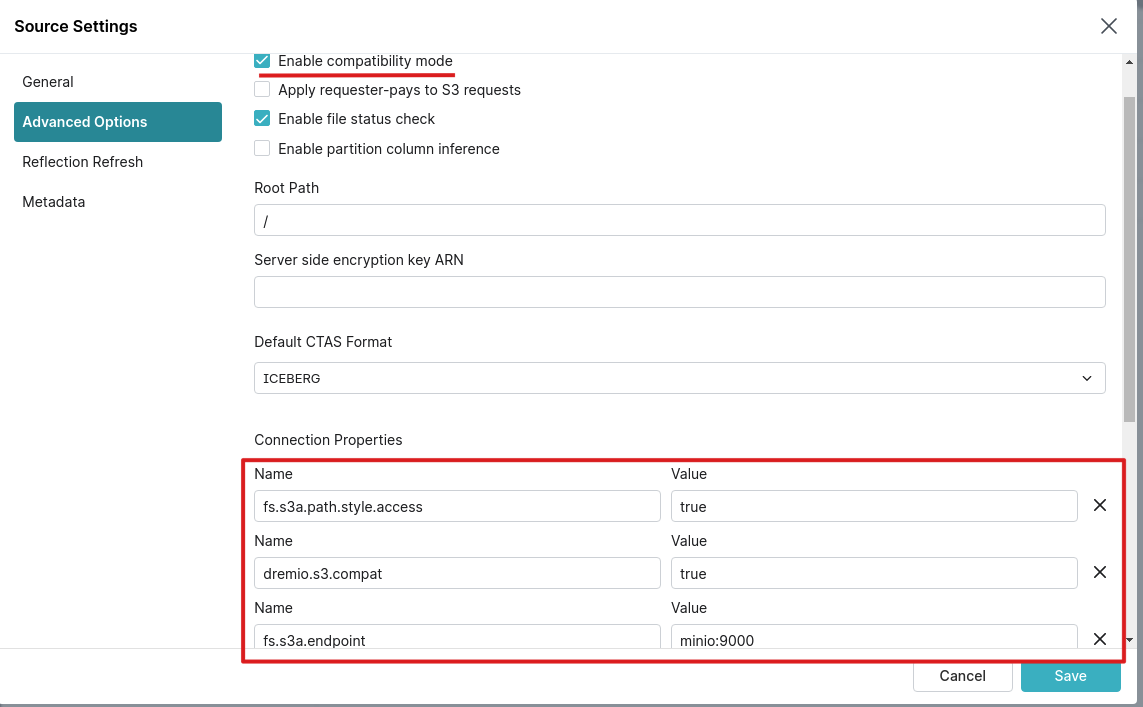
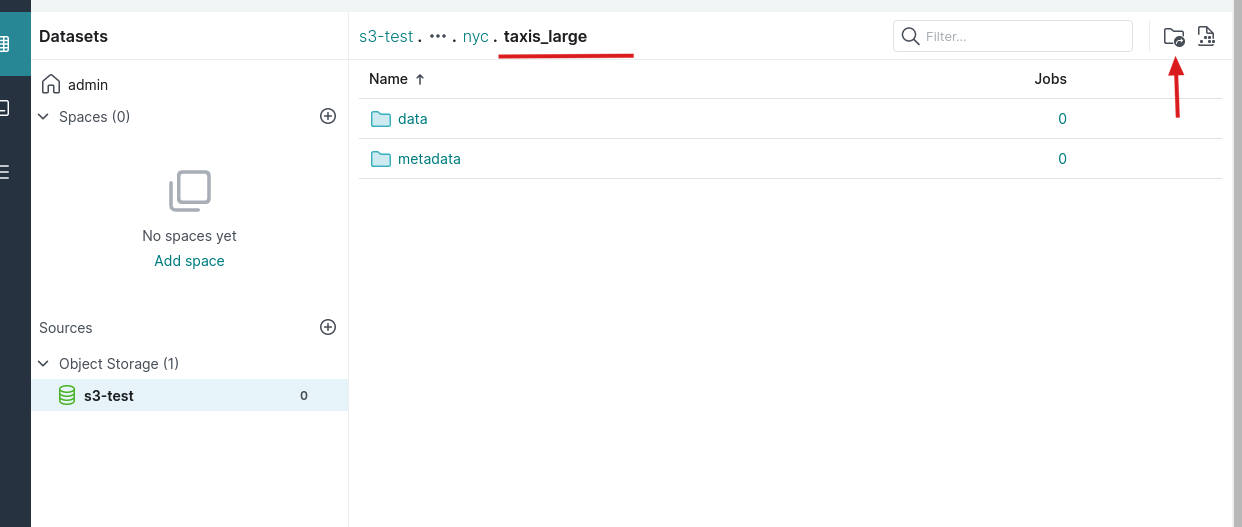
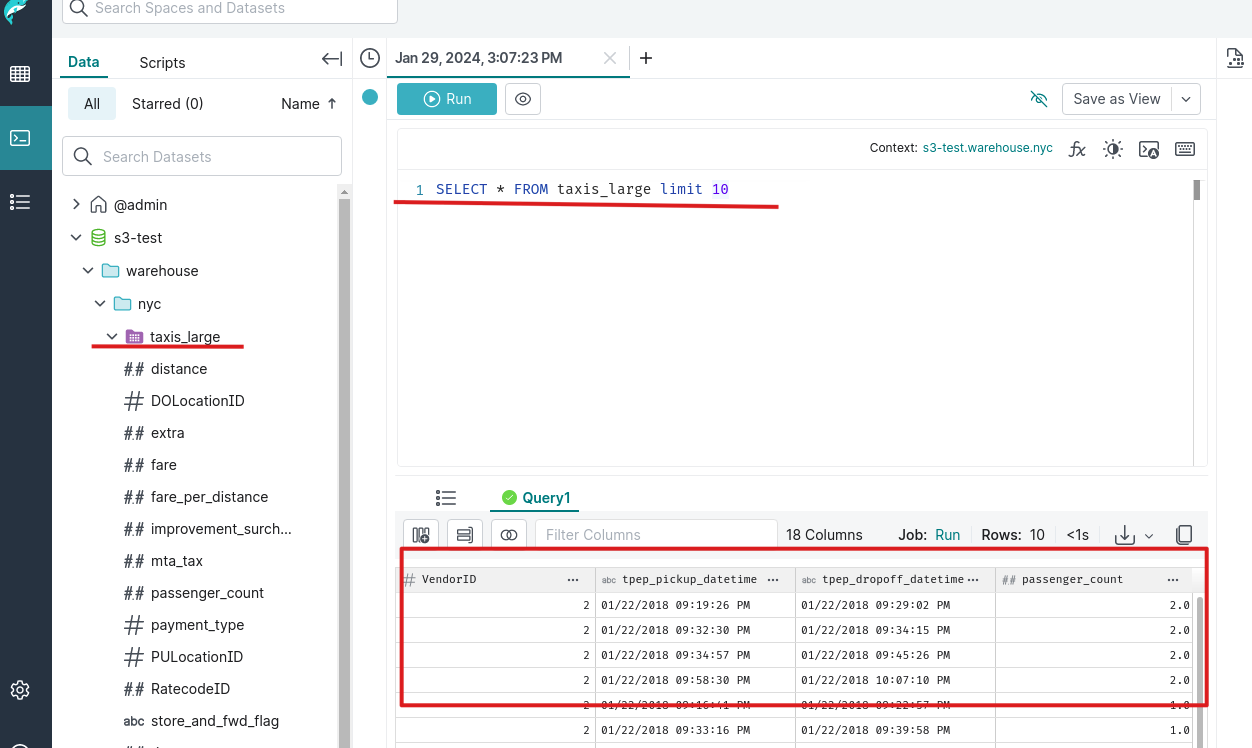
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
| import logging
import os
from pyspark import SparkConf
from pyspark import SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, LongType, DoubleType, StringType
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
logger = logging.getLogger("MinIOSparkJob")
conf = (
SparkConf()
.set("spark.sql.extensions",
"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.set("spark.sql.catalog.demo", "org.apache.iceberg.spark.SparkCatalog")
.set("spark.sql.catalog.demo.io-impl", "org.apache.iceberg.aws.s3.S3FileIO")
.set("spark.sql.catalog.demo.warehouse", os.getenv("WAREHOUSE", "s3a://openlake/warehouse/"))
.set("spark.sql.catalog.demo.s3.endpoint", os.getenv("ENDPOINT", "play.min.io:50000"))
.set("spark.sql.defaultCatalog", "demo")
.set("spark.sql.catalogImplementation", "in-memory")
.set("spark.sql.catalog.demo.type", "hadoop")
.set("spark.executor.heartbeatInterval", "300000")
.set("spark.network.timeout", "400000")
)
spark = SparkSession.builder.config(conf=conf).getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
def load_config(spark_context: SparkContext):
spark_context._jsc.hadoopConfiguration().set("fs.s3a.access.key", os.getenv("AWS_ACCESS_KEY_ID", "openlakeuser"))
spark_context._jsc.hadoopConfiguration().set("fs.s3a.secret.key",
os.getenv("AWS_SECRET_ACCESS_KEY", "openlakeuser"))
spark_context._jsc.hadoopConfiguration().set("fs.s3a.endpoint", os.getenv("ENDPOINT", "play.min.io:50000"))
spark_context._jsc.hadoopConfiguration().set("fs.s3a.connection.ssl.enabled", "true")
spark_context._jsc.hadoopConfiguration().set("fs.s3a.path.style.access", "true")
spark_context._jsc.hadoopConfiguration().set("fs.s3a.attempts.maximum", "1")
spark_context._jsc.hadoopConfiguration().set("fs.s3a.connection.establish.timeout", "5000")
spark_context._jsc.hadoopConfiguration().set("fs.s3a.connection.timeout", "10000")
load_config(spark.sparkContext)
schema = StructType([
StructField('VendorID', LongType(), True),
StructField('tpep_pickup_datetime', StringType(), True),
StructField('tpep_dropoff_datetime', StringType(), True),
StructField('passenger_count', DoubleType(), True),
StructField('trip_distance', DoubleType(), True),
StructField('RatecodeID', DoubleType(), True),
StructField('store_and_fwd_flag', StringType(), True),
StructField('PULocationID', LongType(), True),
StructField('DOLocationID', LongType(), True),
StructField('payment_type', LongType(), True),
StructField('fare_amount', DoubleType(), True),
StructField('extra', DoubleType(), True),
StructField('mta_tax', DoubleType(), True),
StructField('tip_amount', DoubleType(), True),
StructField('tolls_amount', DoubleType(), True),
StructField('improvement_surcharge', DoubleType(), True),
StructField('total_amount', DoubleType(), True)])
df = spark.read.option("header", "true").schema(schema).csv(
os.getenv("INPUT_PATH", "s3a://openlake/spark/sample-data/taxi-data.csv"))
df.write.mode("overwrite").saveAsTable("nyc.taxis_large")
count_df = spark.sql("SELECT COUNT(*) AS cnt FROM nyc.taxis_large")
total_rows_count = count_df.first().cnt
logger.info(f"Total Rows for NYC Taxi Data: {total_rows_count}")
spark.sql("ALTER TABLE nyc.taxis_large RENAME COLUMN fare_amount TO fare")
spark.sql("ALTER TABLE nyc.taxis_large RENAME COLUMN trip_distance TO distance")
spark.sql(
"ALTER TABLE nyc.taxis_large ALTER COLUMN distance COMMENT 'The elapsed trip distance in miles reported by the taximeter.'")
spark.sql("ALTER TABLE nyc.taxis_large ALTER COLUMN distance AFTER fare")
spark.sql("ALTER TABLE nyc.taxis_large ADD COLUMN fare_per_distance FLOAT AFTER distance")
snap_df = spark.sql("SELECT * FROM nyc.taxis_large.snapshots")
snap_df.show()
logger.info("Populating fare_per_distance column...")
spark.sql("UPDATE nyc.taxis_large SET fare_per_distance = fare/distance")
logger.info("Checking snapshots...")
snap_df = spark.sql("SELECT * FROM nyc.taxis_large.snapshots")
snap_df.show()
res_df = spark.sql("""SELECT VendorID
,tpep_pickup_datetime
,tpep_dropoff_datetime
,fare
,distance
,fare_per_distance
FROM nyc.taxis_large LIMIT 15""")
res_df.show()
logger.info("Deleting rows from fare_per_distance column...")
spark.sql("DELETE FROM nyc.taxis_large WHERE fare_per_distance > 4.0 OR distance > 2.0")
spark.sql("DELETE FROM nyc.taxis_large WHERE fare_per_distance IS NULL")
logger.info("Checking snapshots...")
snap_df = spark.sql("SELECT * FROM nyc.taxis_large.snapshots")
snap_df.show()
count_df = spark.sql("SELECT COUNT(*) AS cnt FROM nyc.taxis_large")
total_rows_count = count_df.first().cnt
logger.info(f"Total Rows for NYC Taxi Data after delete operations: {total_rows_count}")
logger.info("Partitioning table based on VendorID column...")
spark.sql("ALTER TABLE nyc.taxis_large ADD PARTITION FIELD VendorID")
logger.info("Querying Snapshot table...")
snapshots_df = spark.sql("SELECT * FROM nyc.taxis_large.snapshots ORDER BY committed_at")
snapshots_df.show()
logger.info("Querying Files table...")
files_count_df = spark.sql("SELECT COUNT(*) AS cnt FROM nyc.taxis_large.files")
total_files_count = files_count_df.first().cnt
logger.info(f"Total Data Files for NYC Taxi Data: {total_files_count}")
spark.sql("""SELECT file_path,
file_format,
record_count,
null_value_counts,
lower_bounds,
upper_bounds
FROM nyc.taxis_large.files LIMIT 1""").show()
logger.info("Querying History table...")
hist_df = spark.sql("SELECT * FROM nyc.taxis_large.history")
hist_df.show()
logger.info("Time Travel to initial snapshot...")
snap_df = spark.sql("SELECT snapshot_id FROM nyc.taxis_large.history LIMIT 1")
spark.sql(f"CALL demo.system.rollback_to_snapshot('nyc.taxis_large', {snap_df.first().snapshot_id})")
res_df = spark.sql("""SELECT VendorID
,tpep_pickup_datetime
,tpep_dropoff_datetime
,fare
,distance
,fare_per_distance
FROM nyc.taxis_large LIMIT 15""")
res_df.show()
logger.info("Querying History table...")
hist_df = spark.sql("SELECT * FROM nyc.taxis_large.history")
hist_df.show()
count_df = spark.sql("SELECT COUNT(*) AS cnt FROM nyc.taxis_large")
total_rows_count = count_df.first().cnt
logger.info(f"Total Rows for NYC Taxi Data after time travel: {total_rows_count}")
|