之前用k3s搭建了大数据环境,但是发现不是特别方便,并且会反复修改,因此考虑到实验的便捷性又用docker搭了一下开发环境,所有的物料链接见https://github.com/henrywangx/dev-cluster
Dev cluster搭建
1.安装
前提:docker和docker-compose已经安装
1.拉起容器
1 | make up |
2.到 minio中国下载 下载mc客户端
3.添加dev集群到mc
1 | mc config host add dev http://localhost:9000 minio minio123 --api s3v4 |
4.创建minio的accesskey/secret, 并保存到本地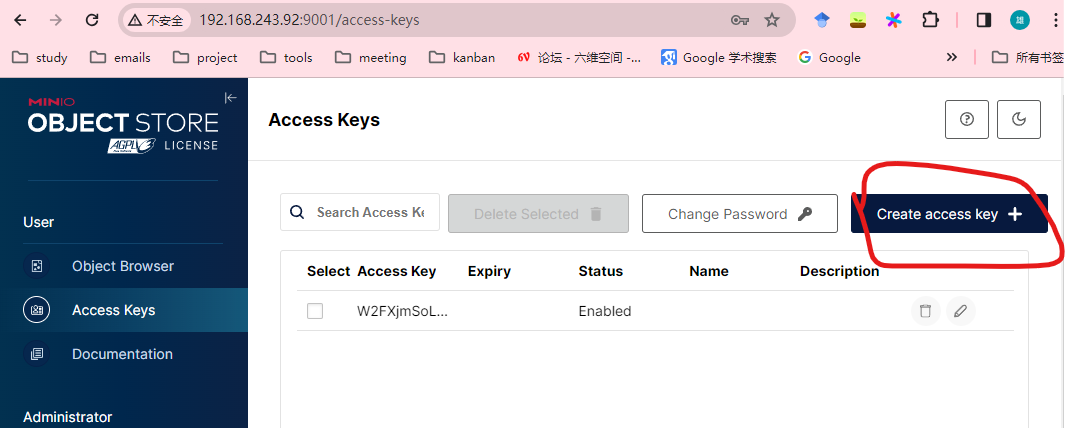
5.使用minio的access key信息更新.env文件
1 | # AWS_REGION is used by Spark |
重新拉起容器
1 | make up |
2.数据准备
1.创建bucket openlake/spark/sample-data/
1 | # 输入bucket |
2.下载出租车数据拷贝到minio中
1 | wget https://data.cityofnewyork.us/api/views/t29m-gskq/rows.csv ./ |
3.运行spark任务
1.网页访问jupyter地址: localhost:8888
2.运行spark-minio.py脚本
1 | python3 spark-minio.py |
3.查看spark管理页面:localhost:8080和jupyter的4040端口localhost:4040,分别可以查看运行的application信息和job的详情信息
application信息: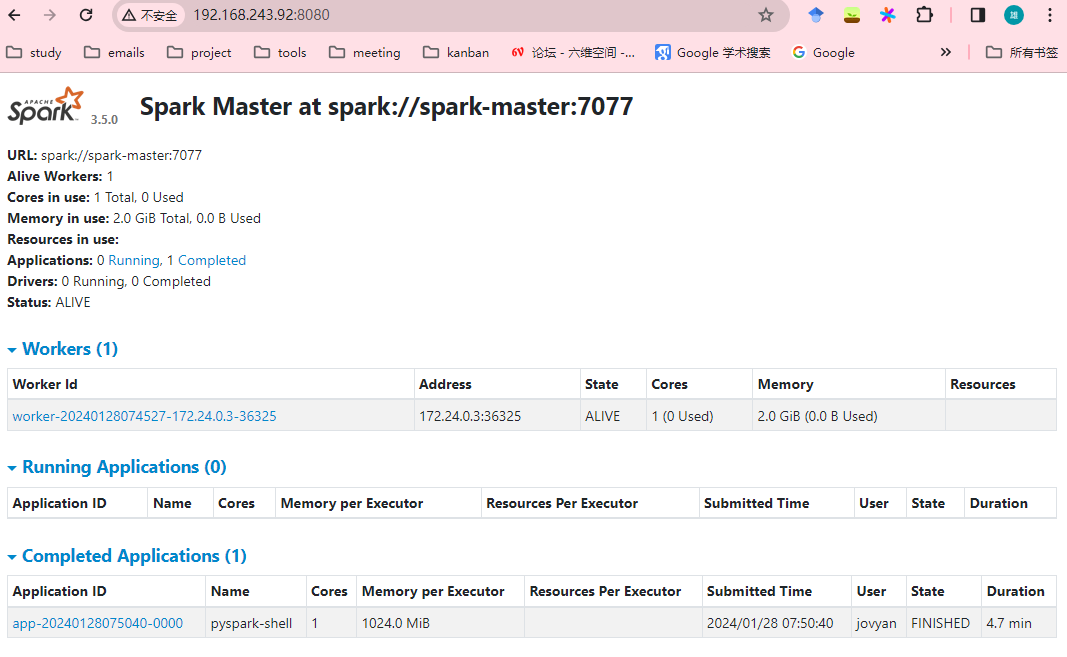
job详情: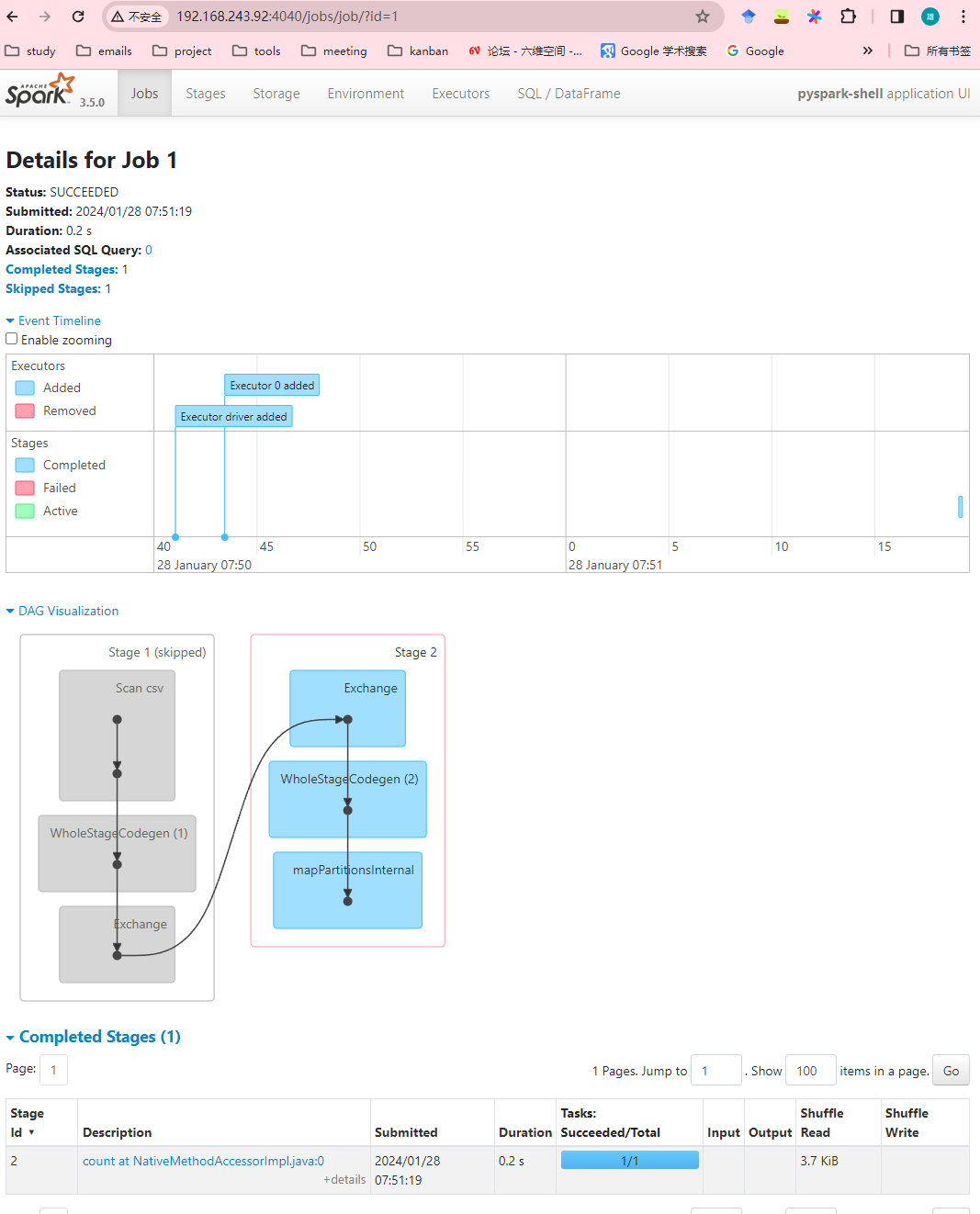
4.等待python执行完毕,查看结果,可以看到外面算出来超过6名乘客的taxi为898
1 | jovyan@jupyter-lab:~$ python3 spark-minio.py |
4.使用pyspark-iceberg管理table
1.创建warehouse bucket
1 | mc mb dev/warehouse |
2.运行spark-iceberg-minio.py
1 | python3 spark-iceberg-minio.py |
5.配置dremio
1.登录dremio页面:localhost:9047,创建s3的source
s3 source配置: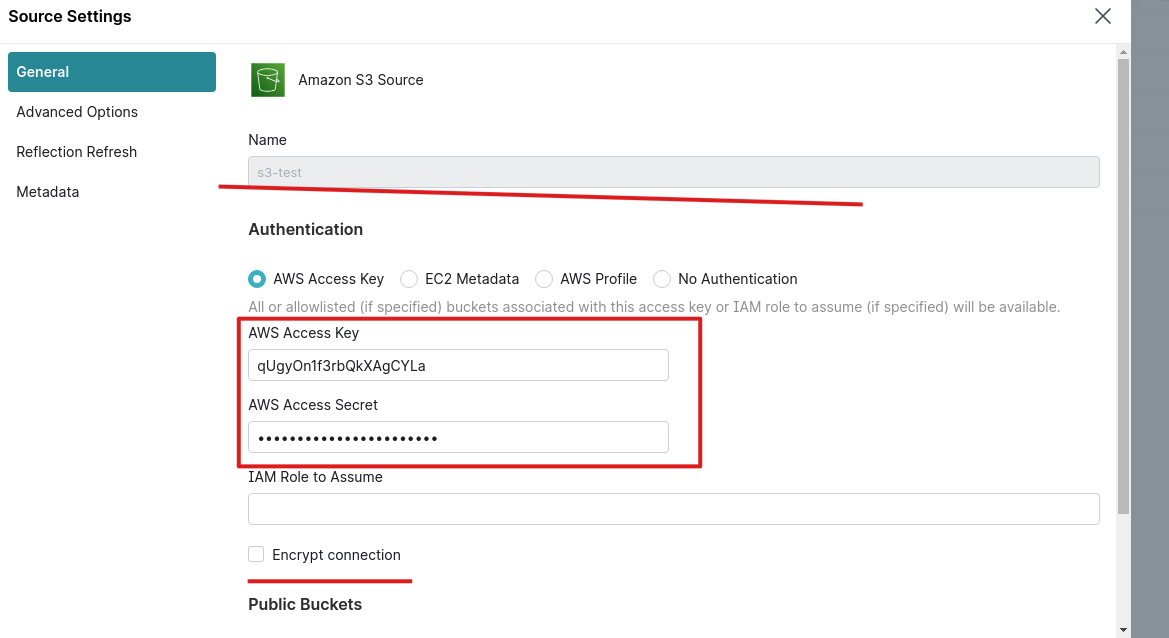
s3 advanced配置:
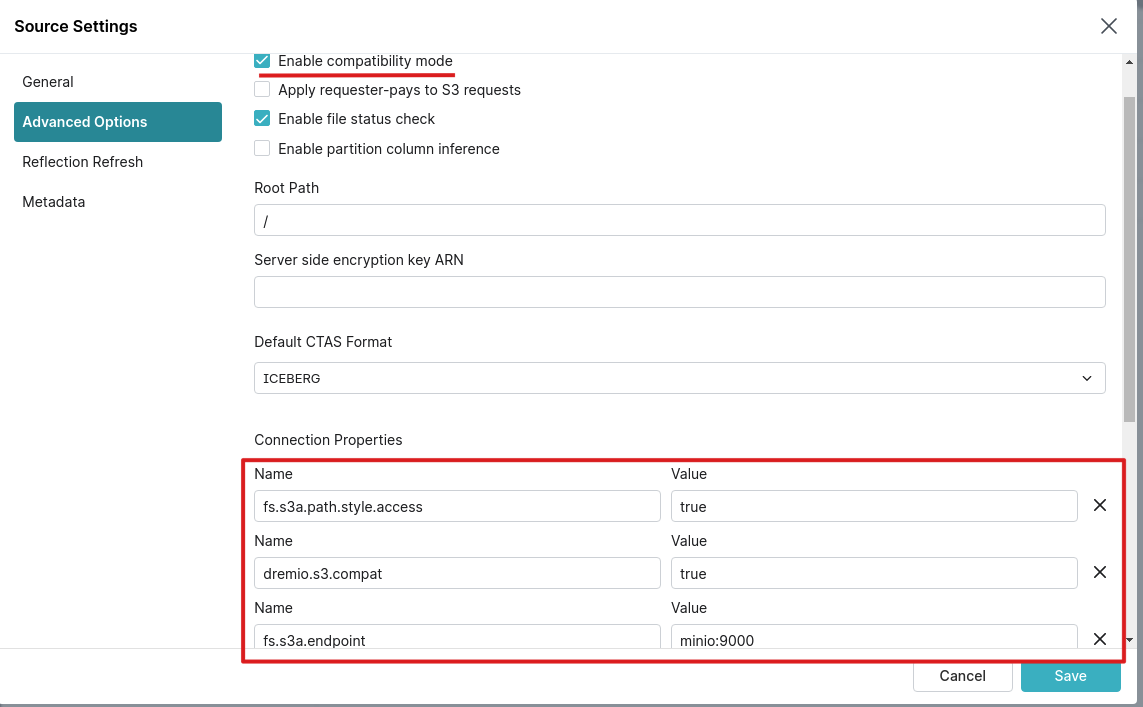
s3配置这里加了以下配置:
fs.s3a.path.style.access:truefs.s3a.endpoint:http://minio:9000dremio.s3.compat:true- 勾选enable compatibility mode, 因为我们是minio
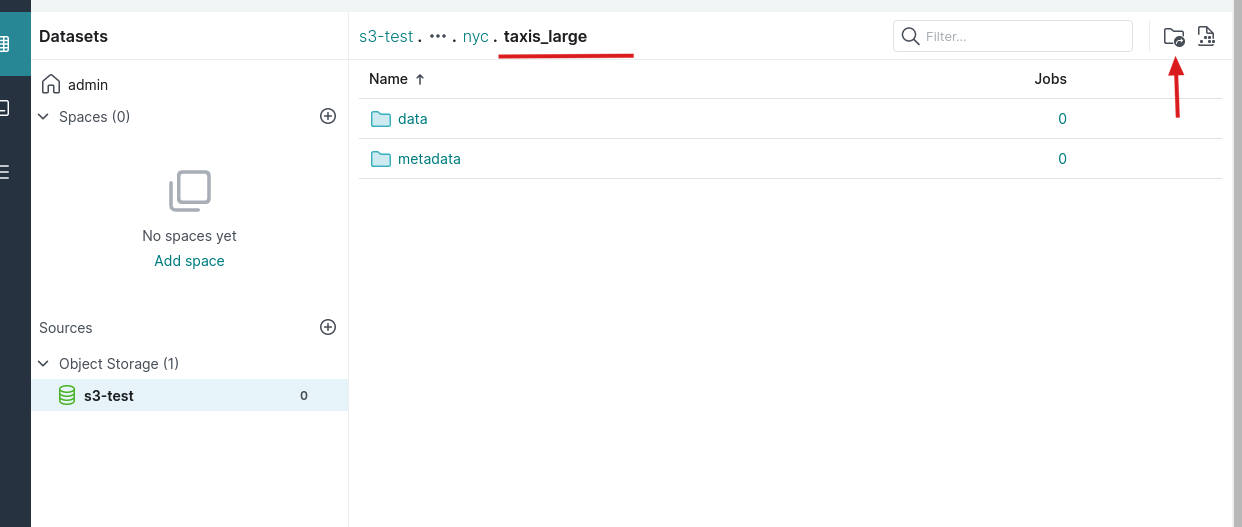
2.format table为iceberg,进入到nyc.taxis_large这个目录,然后点击format table的按钮,保存为iceberg
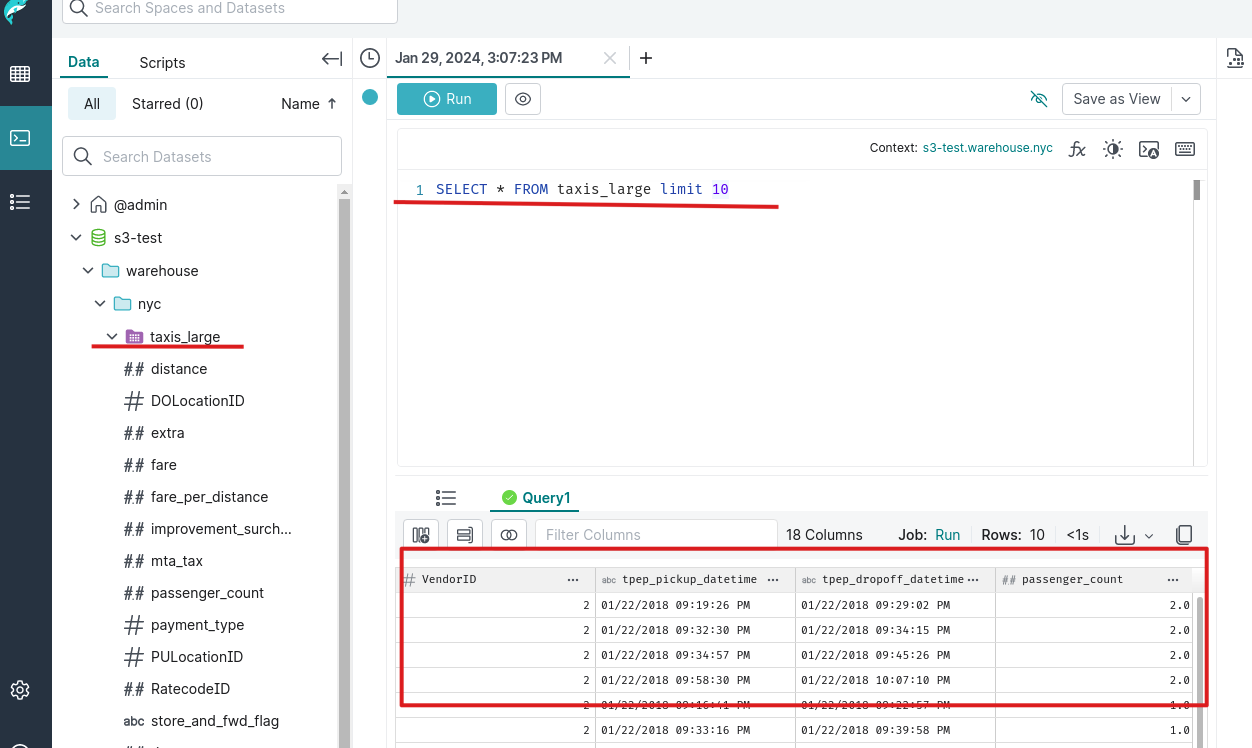
3.format为iceberg后,我们就能发现一个table,选中table,运行sql,发现我们可以用sql来操作iceberg表了,哈哈
1 | SELECT * FROM taxis_large limit 10 |
参考
https://www.cnblogs.com/rongfengliang/p/17970071
https://github.com/minio/openlake/tree/main
https://www.linkedin.com/pulse/creating-local-data-lakehouse-using-alex-merced/
https://medium.com/@ongxuanhong/dataops-02-spawn-up-apache-spark-infrastructure-by-using-docker-fec518698993
https://medium.com/@ongxuanhong/are-you-looking-for-a-powerful-way-to-streamline-your-data-analytics-pipeline-and-produce-cc13ea326790